Baardskeerder’s transaction strategy
Posted: November 28, 2011 Filed under: Baardskeerder, OCaml, Programming, Research | Tags: baardskeerder, compaction, OCaml, transactions Leave a commentBaardskeerder is a simple embedded database based around an append-only B-treeish datastructure.
It’s a dictionary that also supports range queries and transactions.
Baardskeerder is implemented in ocaml, and the main idea is that it will replace Tokyo Cabinet in our Arakoon Key-Value Store.
This post will try to will explain our approach regarding transactions.
Preliminaries
Baardskeerder appends slabs to a log. Slabs are list of entries, and entries can be
either values, leaves, indexes, or commits. Suppose we start with an empty log, and add a first update (set “f” “F”).
Baardskeerder builds a slab that looks like this:
Value "F" Leaf ["f", Inner 0] Commit (Inner 1)
This slab gets serialized, and added to a log, which looks like this:
Value "F" Leaf ["f", Outer 0] Commit (Outer 1)
Notice there are Outer and Inner references. Outer ones refer to positions in the Log, while Inner ones refer to the current slab. During serialization, each inner positions needs to be translated into an outer one, while outer positions just can be copied. (In reality, Outer positions are a bit more complex to calculate as the size of entries after serialization influences them, but I’ve abstracted away from that problem here)
When a slab is ready to be serialized and added, it always ends with a Commit node. This commit node is necessary as there might be a calamity while writing out the serialized slab and it might not end up entirely in the log. So after a successful update, the last entry in the log is a Commit pointing to the current root node.
To fully appreciate the difference between slab and log references,
let’s add another update (set “d” “D”).
The new slab looks like this:
Value "D" Leaf ["d", Inner 0; "f", Outer 0] Commit (Inner 1)
The new leaf in the slab refers both to the value at position 0 in the log (Value “F”) and to the value at position 0 in the slab (Value “D”).
After serialization of the slab, and writing it to the log, the log looks like this:
Value "F" Leaf ["f", Outer 0] Commit (Outer 1) Value "D" Leaf ["d", Outer 3; "f", Outer 0] Commit (Outer 4)
Let’s add some more updates to have a more interesting log:
set "h" "H"; set "a" "A"; set "z" "Z"
After which, the log looks like this:
Value "F" Leaf ["f", Outer 0] Commit (Outer 1) Value "D" Leaf ["d", Outer 3; "f", Outer 0] Commit (Outer 4) Value "H" Leaf ["d", Outer 3; "f", Outer 0; "h", Outer 6] Commit (Outer 7) Value "A" Leaf ["a", Outer 9; "d", Outer 3] Leaf ["f", Outer 0; "h", Outer 6] Index Outer 10, ["d", Outer 11] Commit (Outer 12) Value "Z" Leaf ["f", Outer 0; "h", Outer 6; "z", Outer 14] Index Outer 10, ["d", Outer 15] Commit (Outer 16)
This corresponds to the following tree:
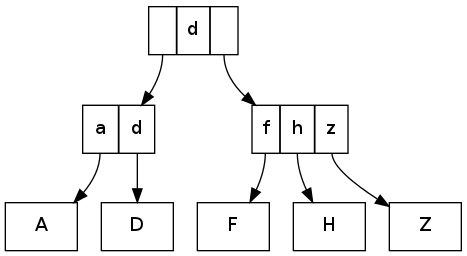
There are several little things to notice here. First, leaves that overflow (size = 4) are split into to new leaves with an Index entry to refer to them both. Also, the entries in the log only refer to previous entries, and, most importantly, nothing ever changes inside the log.
Transactions
Suppose by some accident the process dies while writing the slab, the last slab doesn’t quite fully make it to the log. In the above example, the log might end up just after the value “Z” (or a bit further with half a leaf written).
At the next opening of the log, we’ll search for the last commit, and the log gets truncated just after position 13. As such, the presence of Commit entries that make updates atomic.
They also provide a means to implement non-concurrent transactions. In fact, if we only have a commit entry at the end of a slab, the slab literally is the transaction. At the beginning of the transaction, we create a slab, and we pass it along for all updates. A commit entry is written at the end of the slab, when we’re done. The only added complexity comes from descending the tree:
We must start at the root in the slab (or log if it’s empty) and if we have to jump to an entry, we have to look at its position and jump into the slab if it’s an inner position, and into the log if it’s an outer one. (How to descend a tree is described on more detail a previous blog post)
Our transactional API is simple and clean:
module DBX :
sig
type tx
val get : tx -> k -> v
val set : tx -> k -> v -> unit
val delete : tx -> k -> unit
...
val with_tx : log -> (tx -> unit) -> unit
end
The following code fragment illustrates our transaction api:
let xs = ["f","F";
"d","D";
"h","H";
"a","A";
"z","Z";
]
in
DBX.with_tx log
(fun tx ->
List.iter (fun (k,v) ->
DBX.set tx k v) xs
)
and suppose we apply this transaction to an empty log, we then end up with the following:
Value "F" Leaf ["f", Outer 0] Value "D" Leaf ["d", Outer 2; "f", Outer 0] Value "H" Leaf ["d", Outer 2; "f", Outer 0; "h", Outer 4] Value "A" Leaf ["a", Outer 6; "d", Outer 2] Leaf ["f", Outer 0; "h", Outer 4] Index Outer 7, ["d", Outer 8] Value "Z" Leaf ["f", Outer 0; "h", Outer 4; "z", Outer 10] Index Outer 7, ["d", Outer 11] Commit (Outer 12)
Performance Summary: each transaction boils down to 1 slab, and each slab is written using 1 system call (write).
Slab Compaction
Batching updates in transactions uses less space compared to individual updates, but we still have a lot of dead entries. Take for example the log above. Entries 1,3, 5,8, and 9 are not useful in any way. So it would be desirable to prune them from the slab before they even hit the log.
This turns out to be surprisingly easy.
First we have to find the dead entries, which is done with a simple iteration through the slab, starting from the root, and marking every Inner position as known. When you’re done,
the positions that you didn’t mark are garbage.
type t = { mutable es: entry array; mutable nes: int}
let mark slab =
let r = Array.make (slab.nes) false in
let maybe_mark = function
| Outer _ -> ()
| Inner x -> r.(x) <- true
in
let maybe_mark2 (_,p) = maybe_mark p in
let mark _ e =
match e with
| NIL | Value _ -> ()
| Commit p -> maybe_mark p
| Leaf l -> List.iter maybe_mark2 l
| Index (p0,kps) -> let () = maybe_mark p0 in List.iter maybe_mark2 kps
in
let () = iteri_rev slab mark in
let () = r.(slab.nes -1) <- true in
r
After we have marked the dead entries, we iterate through the slab again, from position 0 towards the end, and build a mapping that tells you how to translate an old Inner position to a new Inner position.
let mapping mark =
let s = Array.length mark in
let h = Hashtbl.create s in
let rec loop i o =
if i = s then h
else
let v = mark.(i) in
let i' = i + 1 in
let () = Hashtbl.add h i o in
let o' = if v then o + 1 else o in
loop i' o'
in
loop 0 0
The last phase is the actual rewriting of the slab, without the dead entries. This again is a simple iteration.
let rewrite s s_mark s_map =
let lookup_pos = function
| Outer x -> Outer x
| Inner x -> Inner (Hashtbl.find s_map x)
in
let rewrite_leaf kps = List.map (fun (k,p) -> (k,lookup_pos p)) kps in
let rewrite_index (p0,kps) = (lookup_pos p0 , rewrite_leaf kps) in
let rewrite_commit p = lookup_pos p in
let esa = s.es in
let size = s.nes in
let r = Array.create size NIL in
let rec loop c i =
if i = size
then { es = r; nes = c}
else
begin
let i' = i + 1 in
let a = s_mark.(i) in
if a then
let e = esa.(i) in
let e' = match e with
| Leaf l -> Leaf (rewrite_leaf l)
| Index i -> Index (rewrite_index i)
| Commit p -> Commit (rewrite_commit p)
| Value _
| NIL -> e
in
let () = r.(c) <- e' in
let c' = c + 1 in
loop c' i'
else
loop c i'
end
in
loop 0 0
Gluing it all together:
let compact s = let s_mark = mark s in let s_map = mapping s_mark in rewrite s s_mark s_map
If we take a look at the slab for our example transaction of 5 sets before compaction
Value "F" Leaf ["f", Inner 0] Value "D" Leaf ["d", Inner 2; "f", Inner 0] Value "H" Leaf ["d", Inner 2; "f", Inner 0; "h", Inner 4] Value "A" Leaf ["a", Inner 6; "d", Inner 2] Leaf ["f", Inner 0; "h", Inner 4] Index Inner 7, ["d", Inner 8] Value "Z" Leaf ["f", Inner 0; "h", Inner 4; "z", Inner 10] Index Inner 7, ["d", Inner 11] Commit (Inner 12)
and after compaction:
Value "F" Value "D" Value "H" Value "A" Leaf ["a", Inner 3; "d", Inner 1] Leaf ["f", Inner 0; "h", Inner 2] Value "Z" Leaf ["f", Inner 0; "h", Inner 2; "z", Inner 6] Index Inner 4, ["d", Inner 7] Commit (Inner 8)
We can see it’s worth the effort.
Of course, the bigger the transaction, the bigger the benefit of compaction.
Question to my 2.5 readers: If you’ve seen a paper, blog, article,… describing this, please be so kind to send me a link.
Offline log compaction
Given Baardskeerder has transactions with slab compaction, we can build a simple and efficient offline compaction algorithm for log files. Start from the root, walk over the tree while building big transactions (as big as you want, or as big as you can afford), and add these to a new log file. When you’re done, you have your compacted log.
Online log compaction
Baardskeerder logs can also return garbage to the filesystem while they are in use, but that will be kept for a later post.
have fun,
Romain.
Baardskeerder is Afrikaans for barber, but also refers to an order of creatures called Solifugae.
A more marketing-prone name would have been Mjolnir Mach3 Ultra Turbo Plus Enterprise Edition with Aloe vera.What’s in a name?
Combining Ocaml Functors and First class modules
Posted: November 21, 2011 Filed under: OCaml, Programming | Tags: OCaml 6 CommentsWe have in our codebase a benchmark module that’s functorized so that we can change the implementation of the module. The benchmark itself is part of a setup that has a driver script and a little server. The driver runs the benchmark with various parameters on different hardware setups, and then posts the results to the server that processes the results and produces graphs, tables, comparisons aso.
But we also want to let the configuration of the driver determine the implementation, and this without recompilation. Ocaml has first class modules (since 3.12), so it must be possible to set it up. After a bit of experimentation, we ended up with a combination of functors and first class modules.
A small example will clarify the solution:
module type Beverage = sig type t val pour : unit -> t val consume : t -> unit end
This is the module type that is needed for the functor.
module Beer = struct
type t = BEER
let pour () =
let () = Printf.printf "... a nice head ... " in
BEER
let consume t = Printf.printf " Ha! Nothing like a good beer to quench the thirst\n"
end
module Whisky = struct
type t = WHISKY
let pour () =
let () = Printf.printf "... 2 fingers of this ...." in
WHISKY
let consume _ = Printf.printf "... Ha! Piss of the Gods!\n"
end
Here comes the functor making good use of the module type defined above.
module Alkie = functor (B:Beverage) -> struct
let rec another = function
| 0 -> ()
| i -> let b = B.pour () in
let () = B.consume b in
another (i-1)
end
We end with the part that does the selection of the module we want to use.
let menu(* : (string, module Beverage) Hashtbl.t (* this should work, but it doesn't *) *) = Hashtbl.create 3
let () = Hashtbl.add menu "Beer" (module Beer : Beverage)
let () = Hashtbl.add menu "Whisky" (module Whisky : Beverage)
let () =
let favourite = ref "Whisky" in
let () = Arg.parse
[("--beverage", Arg.Set_string favourite, Printf.sprintf "which beverage to use (%s)" !favourite)]
(fun s -> raise (Arg.Bad s))
("usage:")
in
let module B = (val (Hashtbl.find menu !favourite) : Beverage) in
let module AlkieB = Alkie(B) in
let () = AlkieB.another 20 in
();;
Actually, this makes me wonder if this problem would not be more elegantly solved using a class type and some factories.
Let’s try that.
class type beverage = object
method consume : unit -> unit
end
class beer = object (self:#beverage)
method consume () = Printf.printf "... beer\n"
end
let make_beer () =
let () = Printf.printf "pouring beer\n" in
let b = new beer in
(b:> beverage)
class whisky = object(self:#beverage)
method consume () = Printf.printf "...drank whisky\n"
end
let make_whisky () =
let () = Printf.printf "pouring whisky\n" in
let b = new whisky in
(b:> beverage)
class alkie p = object (self)
method another n =
if n = 0
then ()
else
let b = p () in
let () = b # consume () in
self # another (n-1)
end
let menu = Hashtbl.create 3
let () = Hashtbl.add menu "Beer" make_beer
let () = Hashtbl.add menu "Whisky" make_whisky
let () =
let favourite = ref "Whisky" in
let () = Arg.parse
[("--beverage", Arg.Set_string favourite, Printf.sprintf "which beverage to use (%s)" !favourite)]
(fun s -> raise (Arg.Bad s))
("usage:")
in
let p = Hashtbl.find menu !favourite in
let a = new alkie p in
a # another 20
;;
For this particular thing, It seems objects are more cooperative than modules.
The important part is you can achieve this kind of composition both with modules and classes, although it may not be very elegant in all cases.
It seems classes and modules have a comparable relationship as closures and modules, which reminds me of a good quote.
The venerable master Qc Na was walking with his student, Anton. Hoping to prompt the master into a discussion, Anton said “Master, I have heard that objects are a very good thing – is this true?” Qc Na looked pityingly at his student and replied, “Foolish pupil – objects are merely a poor man’s closures.”
Chastised, Anton took his leave from his master and returned to his cell, intent on studying closures. He carefully read the entire “Lambda: The Ultimate…” series of papers and its cousins, and implemented a small Scheme interpreter with a closure-based object system. He learned much, and looked forward to informing his master of his progress.
On his next walk with Qc Na, Anton attempted to impress his master by saying “Master, I have diligently studied the matter, and now understand that objects are truly a poor man’s closures.” Qc Na responded by hitting Anton with his stick, saying “When will you learn? Closures are a poor man’s object.” At that moment, Anton became enlightened.
(nicked from here)
have fun,
Romain.
Software Architecture?
Posted: November 15, 2011 Filed under: Architecture, Programming 3 CommentsSoftware Architecture
Introduction
Software Development is one of those activities that is associated with the concept of architecture. So we have software architects working on the software architecture for the project, application, system or whatever. But personally, I think software architecture is a misnomer, an oxymoron, an illusion, a desire or a lie, depending on who utters it in what context. In any case, I’m very much convinced the association between software and architecture is incorrect.
Football architecture
Let me try to explain my view point by starting with a detour to the sports world. If you take a look at sports, like Football for instance, you can see that each team has a goal they want to reach, ranging from winning the competition (whatever that may be) to not being relegated. Apart from the season, there always is the next match, for which coach tries to prepare the team, starting from a comparison of strengths and weaknesses of team and adversary.
Football has strategies. Some teams play kick and rush while others play possession football. Some teams care for the ball, while others like tough defense combined with razor sharp counters (for a notable example, click here). Football has tactics like trick plays (click for a fine example), that can really change the course of a game. Football has an element of luck : some things work out better than anticipated, while sometimes the ball just is against you.
Skill is involved too (a demonstration by Zlatan) and there are many players and coaches (trainers, managers) who have a vision on how the game should be played and who certainly know what they are doing and why they do it.
Now, allow me to ask the following question: Does a football match have architecture? I’m pretty sure your answer would be “of course not”. So then why would software have architecture?
Architecture?
Actually, what is architecture anyway? It stems from the Greek “ἀρχι τέκτων” which roughly translates to “master builder”. So architecture would refer both to what the master builder does (process) and to what the result of his efforts are (artefact). Somehow, somewhere role and semantics shifted a bit, and these days, the architect does not really build anymore, and architecture refers to the activity of designing a structure.
So if Architecture deals with the design(ing) of structure, then what is structure? The structure is that what bares the load. In the context of a building, it’s whole of beams, columns, frames, struts, and other structural members, together with it’s spatial configuration. It’s the thing that, once built, or constructed does not change anymore, because you would have to start over. If you start a search for structure in software, you will find that there is none, or at least, there should not be one.
When working on a software project/product, you have to make choices, and sometimes, you can even see a really good solution to the current set of requirements. The problem is that you know these requirements will change somewhere in the future, and that your ideal solution will be too costly to change. So you apply the “design for change” stratagem, and you deliberately choose to ignore the solution that does yield the best fit to the requirements, but you pick the one that will imply lower costs for the future change of direction.
Basically you’re trying to avoid the software from assuming a certain structure. You’re doing the opposite of architecture. What I’m trying to say is that I think the metaphor is wrong.
I think a better metaphor is to consider software development as a (real-time strategy) game played against the universe. This game involves strategy, tactics, and luck, but it does not involve architecture.
Strategy
There certainly is a strategical aspect in software development. It just doesn’t get a lot of attention, and if it does,
it’s usually in an overly simplified sloganesque language like “Design for change” or “KISS!” or “Separation of concerns”. In fact, when strategy is considered to be a relevant concept in the context of software development, it is almost always seen in relation to the process part, and never to the coding part directly.
Some of the strategic choices that impact chance of success for a project/product a lot, like development ecosystem, programming paradigm, and programming language are hardly ever made at all. Yet, the choices made there are equally important.
For example, Ken Thompson made one of the most successful choices NOT to write, what would eventually become Unix, in assembly language. A lot of people said he was insane, and it would never be fast enough. He was not to be deterred.
One of the worst choices was made by a company (which I shall not name) I worked for in the past. We were building a commercial end-user application in Java for OSX.
The reasoning went something like this:
- Linux users will not pay for software, and Windows users are not willing neither, while Mac users have an open wallet.
- Java is an excellent choice for both client and server side development, and OSX is a good Java platform
Both arguments were defensible but, at the time, 90% of the end users were on windows, so if you target a community with a product that will reach only a percentage of them,
it better be a big community, and not a marginal one.
The Java choice was quite unfortunate, but at the time, they still believed Apple’s promise to make OS X the best Java platform on the planet. Later, it became painfully obvious that Apple changed its mind.
In retrospect, it should have been done in some .net language on Windows, but hindsight is 20/20.
Software tactics
Software development has tactics too. A famous anecdote from M. Abrash in Zen of Graphics Programming goes like this:
Years ago, I worked at a company that asked me to write blazingly fast line-drawing code for an AutoCAD driver. I implemented the basic Bresenham’s line-drawing algorithm; streamlined it as much as possible; special-cased horizontal, diagonal, and vertical lines; broke out separate, optimized routines for lines in each octant; and massively unrolled the loops. When I was done, I had line drawing down to a mere five or six instructions per pixel, and I handed the code over to the AutoCAD driver person, content in the knowledge that I had pushed the theoretical limits of the Bresenham’s algorithm on the 80×86 architecture, and that this was as fast as line drawing could get on a PC. That feeling lasted for about a week, until Dave Miller, who these days is a Windows display-driver whiz at Engenious Solutions, casually mentioned Bresenham’s faster run-length slice line-drawing algorithm.
…
I learned two important safety tips from my line-drawing experience
…
First, never, never, never think you’ve written the fastest possible code. Odds are, you haven’t. Run your code past another good programmer, and he or she will probably say, “But why don’t you do this?” and you’ll realize that you could indeed do that, and your code would then be faster. Or relax and come back to your code later, and you may well see another, faster approach. There are a million ways to implement code for any task, and you can almost always find a faster way if you need to.Second, when performance matters, never have your code perform the same calculation more than once. This sounds obvious, but it’s astonishing how often it’s ignored.
(Btw, I have since discovered examples that contradict his second rule)
An improved algorithm for a standard problem can suddenly make a whole range of applications viable where they were once considered too expensive for current hardware.
Sheer Luck
Nihil sine Strategiam et fortuna omnibus vincit
It’s difficult to find examples of luck in software development as most people being assisted by it have the tendency of disguising it as a stroke of genius. There is nothing wrong with accidentally being in the right place at the right time, and then taking advantage of it. Anyway, in science, they often use the concept of serendipity to explain fortunate coincidences.
Last words
I should wrap up, as this is looking more and more like an essay instead of a blog post.
Don’t misunderstand this rant, I’m not saying you should not plan ahead or think hard before you actually start coding.
But I am warning you that if you start out to create a software architecture, you will probably end up having one. Or as the famous quote goes:
“There’s two kinds of unhappy people: those that didn’t get what they wanted, and those that got it!”.
have fun,
Romain.
PS.
We’re looking for new collegues, software architects can apply too.

